- نُشر في
- ·21 دقيقة للقراءة
وين تروح المحاولة الجاية؟ من الـ bandits للترتيب تحت الضجيج
- Authors

- Name
- هاني الشاطر
خمس مطاعم قريبة من بيتك. واحد منهم غالباً هو الأفضل.
لو الجودة الحقيقية مكتوبة على الباب، المسألة مملّة:
اقرأ الأرقام. رتّب. خذ الأكبر.
بس الأرقام مش مكتوبة. لازم تكتشفها بالأكل. عشا واحد بيعطيك إشارة، مش الحقيقة كلها. يمكن الشيف كان تعبان. يمكن إنت طلبت الطبق الغلط. يمكن المطعم ممتاز وإنت وقعت على أسوأ طبق عنده.
هون أول كسر لفكرة «الترتيب» البسيطة.
إحنا بنحكي كأننا عم نرتّب مطاعم، منتجات، موديلات، إعلانات، لاعبين، أو creators. بس بالأنظمة الحقيقية القيمة اللي بدنا نرتّب عليها غالباً مخفية. ما بنقرأها. بنشتري دليل عنها.
كل محاولة إلها وجهين: بتعطيك نتيجة الآن، وبتغيّر اللي بتعرفه بعدين.
عشان هيك قبل ما نسمّي خوارزميات، افصل بين شغلتين:
- شكل القرار — شو مسموح تختار.
- قناة الـ feedback — شو العالم بيرجعلك بعد ما تختار.
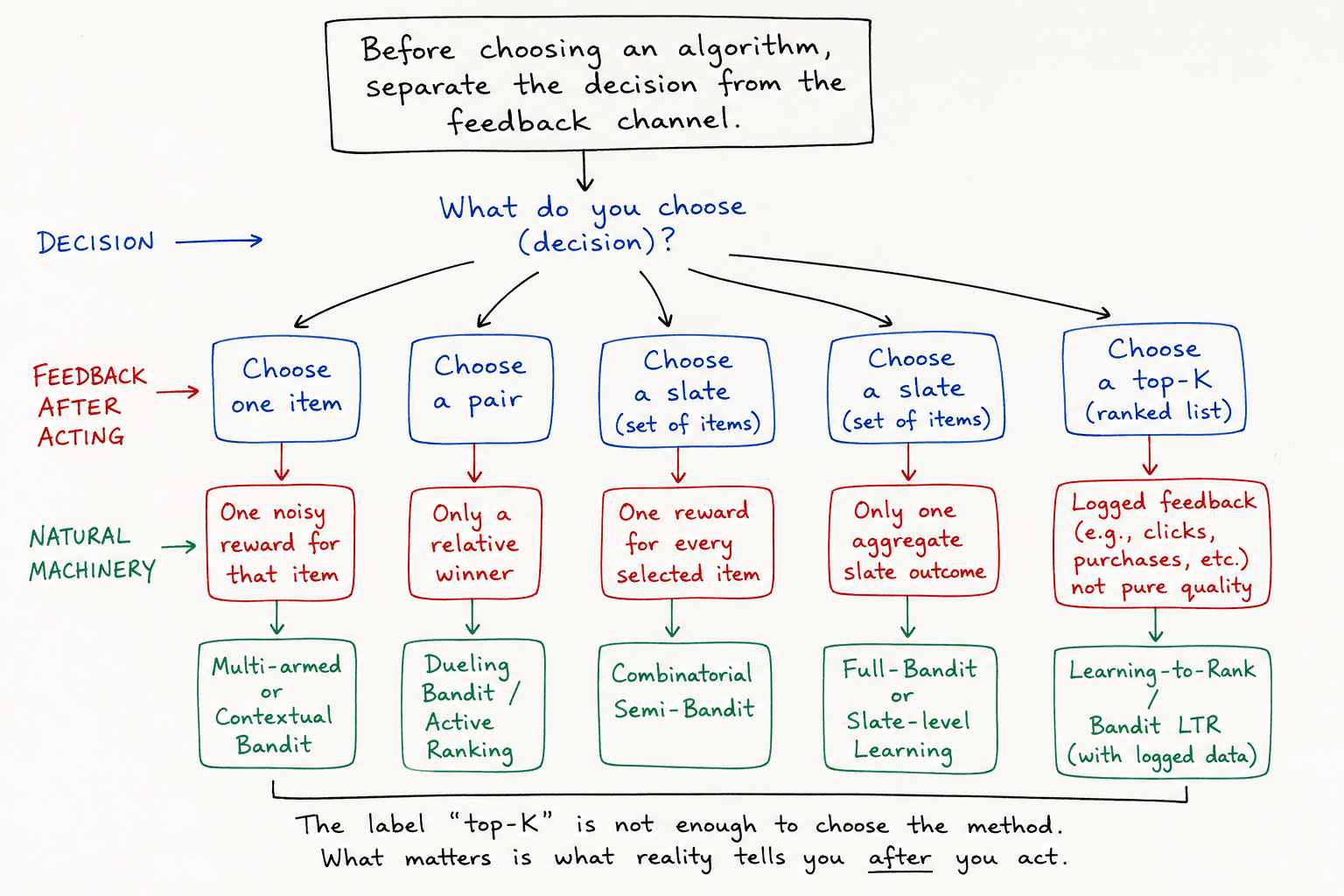
كلمة “top-K” لحالها مش كفاية لاختيار الطريقة. المهم: شو نوع الإشارة اللي بيرجعلك بعد القرار؟
الجزء الأول — الـ multi-armed bandit: نختار العشا
مشكلة المطاعم إلها اسم قديم: multi-armed bandit. استعارة الكازينو بشعة، بس الـ loop مفيد.
كل مطعم هو arm. كل زيارة هي pull. والعشا هو reward.
الأهم هو اللي ما بتشوفه.
إنت ما بتاكل بكل المطاعم بنفس الليلة. ما بيجيك report card كامل. بتختار مطعم واحد، بتشوف نتيجة واحدة فيها ضجيج، والباقي بضل احتمالات.
هاي المعلومة الناقصة هي اللعبة كلها.
الـ regret: ضريبة الجهل المخفية
لو السوشي هو فعلاً أفضل مطعم، وإنت أكلت بمكان أضعف، دفعت ضريبة مخفية. ممكن الليلة تكون لطيفة، بس مقارنة بأفضل خيار متاح، تركت جودة على الطاولة.
Bandit theory بتسمي هاي الضريبة regret:
المعادلة بس bookkeeping. بكل ليلة، قارن المطعم اللي اخترته، ، مع أفضل معدل مخفي، . اجمع الفرق.
الـ regret بيجي من غلطتين عكس بعض.
لو التزمت بدري، ليلة رامن محظوظة ممكن تلبّسك الفائز الغلط. ولو ضلّيت تستكشف للأبد، بتضل تشتري عشا متوسط بعد ما الجواب صار شبه واضح.
سياسة الـ bandit هي القاعدة اللي بتختار الـ pull الجاية. عملياً، هي طريقة لصرف الجهل: أي عدم يقين لسه بستاهل تدفع ثمنه؟
جرّب القرار قبل أسماء الخوارزميات.
استخدم الديمو لتحسّ المقايضة قبل ما تظهر الخوارزميات.
اختار مطاعم لعشرات الليالي. شوف شو بصير لما تثق بالحظ المبكر زيادة، وشو بصير لما تضل تجرّب أماكن واضح إنها متأخرة.
الدرس هو شكل المسألة: الاستكشاف مفيد بس طالما ممكن يغيّر القرار.
أربع طرق لصرف عدم اليقين
ε-greedy. أغلب الوقت، روح على المطعم اللي معدله الحالي أفضل. كل فترة، تجاهل ملاحظاتك وجرب عشوائياً.
هذا بحميك من غلطة مبكرة، بس عنده عادة غبية: حتى بعد ما يصير الفائز واضح، بضل يدفع ضريبة الاستكشاف.
UCB1 — التفاؤل وقت عدم اليقين. قيّم كل arm بـ:
وخذ أعلى score.
هون:
- هو عدد التجارب لحد الآن.
- هو عدد مرات تجربة arm رقم .
- هو متوسط الـ reward المرصود لـ arm رقم .
الحد الثاني،
هو bonus الاستكشاف.
بيكون كبير لما صغير، وبيصغر كل ما يزيد الدليل. UCB مش عم يستكشف عشوائياً؛ هو عم يستكشف وين الغلط لسه ممكن يغيّر القرار.
KL-UCB. UCB1 بيستخدم confidence radius عام. KL-UCB بيستخدم radius شكله Bernoulli.
لـ click/no-click أو purchase/no-purchase، هو بيسجّل arm بأعلى success rate ممكن في بحيث:
KL هون هي مسافة إحصائية بين معدل Bernoulli اللي شفته، ، والمعدل المرشح .
المعنى: خذ أعلى قيمة متفائلة لسه معقولة إحصائياً تحت بيانات Bernoulli اللي شفتها.
الانتقال من 2% لـ 5% مش نفس الحركة الإحصائية مثل 50% لـ 53%، مع إن الاثنين ثلاث نقاط. KL-UCB بيحترم هاي الهندسة.
Thompson sampling — خلّي المعتقدات تتسابق. احتفظ بتوزيع احتمالي لكل arm، مش متوسط واحد. بكل جولة، اسحب جودة محتملة من كل belief وروح على الأعلى.
مطعم جرّبته قليل belief تبعه واسع، فمرات بطلع عالي وبياخذ فرصة. مطعم معروف إنه سيء belief تبعه ضيق ومنخفض، فبالكاد بفوز. ما في حدا بقلك «استكشف الآن». الاستكشاف بيطلع من عدم اليقين.
الحالة الصعبة هي لما أفضل مطعمين قريبين.
Pure exploitation ممكن يتوّج الفائز الغلط بعد وجبة محظوظة بدري. ε-greedy بتحميك من جزء من هذا بإجبار استكشاف عشوائي، وبعدها بتضل تدفع ضريبة العشوائية لما تصير أقل فائدة. UCB وKL-UCB بصرفوا الاستكشاف أكثر على arms ناقصة التجربة. Thompson بعمل شيء قريب عن طريق posterior samples.
KL-UCB مفيد لما الـ reward قريب من Bernoulli، مثل clicks أو purchases. بس بالإنتاج في فخ: لو الـ clicks متأخرة، أو منحازة بالرتبة، أو مخلوطة بطريقة العرض، الـ bound الأدق ممكن يصير دقة وهمية.
افتح الكود: Bernoulli bandit مختصر
import math
import numpy as np
def bernoulli_kl(p, q):
eps = 1e-12
p = min(1 - eps, max(eps, p))
q = min(1 - eps, max(eps, q))
return p * math.log(p / q) + (1 - p) * math.log((1 - p) / (1 - q))
def kl_ucb(mean, pulls, t, c=3.0):
if mean >= 1.0:
return 1.0
budget = (math.log(max(t, 2)) + c * math.log(math.log(max(t, 3)))) / pulls
low, high = mean, 1.0 - 1e-12
for _ in range(32):
candidate = (low + high) / 2
if bernoulli_kl(mean, candidate) <= budget:
low = candidate
else:
high = candidate
return low
def choose_arm(successes, pulls, t, policy, rng):
unseen = np.flatnonzero(pulls == 0)
if len(unseen):
return int(rng.choice(unseen))
means = successes / pulls
if policy == "epsilon_greedy":
return int(rng.integers(len(pulls))) if rng.random() < 0.10 else int(np.argmax(means))
if policy == "ucb1":
scores = means + np.sqrt(2.0 * np.log(t) / pulls)
return int(np.argmax(scores))
if policy == "kl_ucb":
scores = np.array([kl_ucb(means[a], pulls[a], t) for a in range(len(pulls))])
return int(np.argmax(scores))
if policy == "thompson":
samples = rng.beta(1 + successes, 1 + pulls - successes)
return int(np.argmax(samples))
def update(successes, pulls, arm, reward):
pulls[arm] += 1
successes[arm] += reward
الـ pull المفيد غالباً هو اللي نتيجته ممكن تغيّر رأيك.
الـ context بيغيّر الجواب
معدل واحد لكل مطعم نظيف. وكثير مرات كذّاب.
غدا سريع، عزومة عيلة، غدا شغل، ضيوف جايين من برا، وعشا لحالك بيوم مطر مش نفس القرار. مطعم ممكن يكون غلط لواحدة وممتاز لثانية.
هاي فكرة contextual bandit: شوف الموقف أولاً، بعدين اختار.
بالنسخة الخطية البسيطة، الموقف هو feature vector اسمه . للعشا، الـ features ممكن تكون: سريع، هادي، رخيص، مناسب للأطفال، spicy، أو مناسب لمجموعة. كل arm إلها response vector اسمه .
التوقع هو:
الـ dot product بسأل سؤال أهم من «قديش المطعم جيد؟»
بسأل:
قديش هذا المطعم مناسب لهذا الموقف؟
هون الـ context بيفيد. عشا عيلة ناجح مش دليل عن هاي الليلة فقط؛ هو بيعلّم الموديل عن مواقف عائلية ثانية. غدا شغل سريع بيعلّم عن سياقات quick-work ثانية. الموديل بيوقف يخلط مواقف ما لازم تنخلط.
LinUCB هو UCB ومعه هالموديل الخطي. لكل arm، بيحتفظ بإحصاءات تقدّر :
ومنهم:
وبعدين بختار arm بأكبر score متفائل:
الحد الأول هو reward متوقع بالسياق الحالي. الحد الثاني هو عدم اليقين في هاي المنطقة من feature space.
فالمجهول تغيّر. مش:
قديش هذا المطعم جيد؟
بل:
بأي مواقف هذا المطعم جيد؟
تحذير إنتاجي مهم: الـ context لازم يكون معروف قبل القرار. إذا عرفته بعد العشا، click، purchase، delivery، أو complaint، فهو feedback — مش context.
في الديمو، السياسة غير السياقية بتحتفظ بمتوسط واحد لكل مطعم. LinUCB بيشرط الاختيار على الموقف أولاً.
لما نفس المطعم يكون جيد بسياق وسيء بسياق ثاني، السياسة السياقية لازم تخسر regret أقل لأنها بتوقف تجمع عشاوات غير متوافقة في معدل واحد.
افتح الكود: disjoint LinUCB بـ NumPy
import numpy as np
class DisjointLinUCB:
def __init__(self, n_arms, dim, alpha=0.8, l2=1.0):
self.alpha = alpha
self.A = [l2 * np.eye(dim) for _ in range(n_arms)]
self.b = [np.zeros(dim) for _ in range(n_arms)]
def choose_arm(self, x):
scores = []
for A_a, b_a in zip(self.A, self.b):
theta_a = np.linalg.solve(A_a, b_a)
predicted_reward = x @ theta_a
uncertainty = np.sqrt(x @ np.linalg.solve(A_a, x))
scores.append(predicted_reward + self.alpha * uncertainty)
return int(np.argmax(scores))
def update(self, arm, x, reward):
self.A[arm] += np.outer(x, x)
self.b[arm] += reward * x
# x must contain only information known before the action.
# Example: [1, is_lunch, is_family_dinner, is_raining, mobile_user].
arm = policy.choose_arm(x_t)
reward = observe_reward(arm)
policy.update(arm, x_t, reward)
أحياناً ما عندك reward رقمي أصلاً.
بالرياضة، صعب تقول اللاعب قوته 173. أسهل تشوف إن اللاعب A غلب B. ومع ردود LLM، صعب تعطي جواب رقم جودة نظيف؛ أسهل تسأل judge: أي جواب أحسن؟
فالـ feedback بتتغيّر مرة ثانية. الفعل ما عاد arm واحدة.
صار زوج.
بتختار عنصرين، وبتشوف مين فاز.
الجزء الثاني — Pairwise ranking: لما الـ arm تصير مباراة
تمن لاعبين. ما في stat sheet. ما في رقم مهارة نظيف.
بتقدر تنزّل أي لاعبين يلعبوا وتشوف مين فاز.
المباراة مقارنة فيها ضجيج. فرق المهارة بغيّر انحياز القرعة؛ ما بيلغي القرعة. اللاعب القوي غالباً يغلب الضعيف. اللاعبين القريبين أقرب لعملة.
مع لاعبين عندك أزواج ممكنة. مقارنة الكل غالية على scale صغير، ومستحيلة على product scale.
فالمشكلة مش بس تقدّر الجدول. المشكلة تقرّر أي مقارنة لسه إلها قيمة.
إذا لاعب جديد غلب بطل العالم، لعبه ضد الضعاف بعدين ما بعلمك كثير. المقارنات المفيدة بتكون حوالين الحدود اللي لسه مش محسومة.
مين لازم يلعب المباراة الجاية؟
هذا لسه ترتيب، بس الـ comparison oracle فيها ضجيج. بالكتاب، المقارنة بتحكي الحقيقة. هون الأفضل بس غالباً بيفوز.
الفعل هو زوج. والـ feedback bit واحد: مين فاز؟
ما في score للاعب A. ما في score للاعب B. ما في رقم جودة مطلق.
الافتراض البنيوي القياسي هو Bradley-Terry.
كل عنصر إله skill score مخفي. واحتمالات الفوز بتيجي من فرق الـ scores:
scores متساوية تعطي 50/50. gap كبير يعطي نتيجة شبه مؤكدة. الـ scale المطلق مش مهم؛ الفرق هو اللي يشتغل.
قوة الموديل هي transfer. إذا A غلب B، وB غلب C، الـ scale المشترك صار يحكي شيء عن A مقابل C قبل ما يلعبوا.
الجزء المؤلم هو الحدود. تقريباً، تمييز skill gap صغير بثقة بده:
مقارنات.
الفروقات الكبيرة بتنحسم بسرعة. الـ near ties بتاكل الميزانية.
من pairwise feedback لـ skill ratings
Batch fit. خذ كل المباريات، وfit scores لنموذج Bradley-Terry بحيث النتائج اللي شفتها تصير أكثر احتمالاً.
إذا A غلب B كثير، الـ fit بدفع A فوق B لحد ما يقرّب من التاريخ. إذا B غلب C كثير، B بطلع فوق C. وبما إن الموديل عنده scale واحد، هالحقائق بتحرّك A بالنسبة لـ C حتى لو ما لعبوا.
الكود تحت بيستخدم batch update قياسي. ابدأ كل لاعب بنفس strength موجب. كرّر السؤال: given strengths الحالية للكل، قديش لازم تكون strength اللاعب حتى تفسّر wins تبعته؟
بعد كل pass، normalize. Bradley-Terry بهمّه relative strength؛ ضرب كل strengths بنفس الثابت ما بغيّر أي احتمال مباراة.
رتّب الـ fitted skills وبيطلع معك ranking. نظيف، بس مش رخيص: refit من الصفر بعد كل مباراة ما بيسكّل.
Online fit: Elo. Elo هي نسخة streaming من نفس الفكرة. خليك ماسك rating واحد لكل لاعب، وحدّثه بعد كل مباراة.
الفوز بنقل points من الخاسر للفائز. حجم الحركة بيعتمد على المفاجأة.
غلب بطل العالم، لازم تكسب كثير. غلب مبتدئ، تقريباً لا شيء. خسر من لاعب أضعف بكثير، rating لازم ينزل بقوة.
صيغة واحدة لهالتحديث هي خطوة logistic regression. إذا غلب :
هنا هو احتمال الموديل قبل المباراة إن يغلب . التحديث هو المفاجأة: .
لو كان favourite قوي، الحركة صغيرة. لو كان underdog، الحركة كبيرة.
افتح الكود: Bradley–Terry batch fit وElo online
import numpy as np
def fit_bradley_terry_mm(wins, iterations=100, eps=1e-9):
"""
wins[i, j] is the number of times item i beat item j.
Returns log-strengths; sorting them gives the Bradley–Terry ranking.
"""
wins = np.asarray(wins, dtype=float)
pair_games = wins + wins.T
total_wins = wins.sum(axis=1)
n_items = len(wins)
strength = np.ones(n_items)
for _ in range(iterations):
updated = strength.copy()
for i in range(n_items):
denominator = 0.0
for j in range(n_items):
if i != j and pair_games[i, j] > 0:
denominator += pair_games[i, j] / (strength[i] + strength[j])
if denominator > 0:
updated[i] = max(total_wins[i], eps) / denominator
# Bradley–Terry is identifiable only up to an additive constant in log-space.
updated /= np.exp(np.mean(np.log(np.maximum(updated, eps))))
strength = updated
return np.log(np.maximum(strength, eps))
def elo_update(rating, i, j, winner, learning_rate=0.25):
"""One online logistic-regression step after i versus j."""
p_i_wins = 1.0 / (1.0 + np.exp(-(rating[i] - rating[j])))
target_i = 1.0 if winner == i else 0.0
delta = learning_rate * (target_i - p_i_wins)
rating[i] += delta
rating[j] -= delta
return rating
# Batch: scores = fit_bradley_terry_mm(wins)
# Online: rating = elo_update(rating, i, j, winner)
الـ loop هو:
قدّر المهارات من المباريات → اقرأ الترتيب بفرزها → جدوِل المباراة الجاية.
وين تصرف المباريات؟
المباراة الجاية لازم تروح لمكان النتيجة فيه ممكن تحرّك الترتيب.
مباراة غير متكافئة غالباً بتأكّد اللي الموديل أصلاً مصدّقه. لو #1 غلب #8، الجدول بالكاد بيتحرك.
المباراة المتقاربة مختلفة. النتيجتين معقولتين، وكل نتيجة بتعلّمك شيء عن ترتيب محلي لسه مش محسوم.
scheduler مفيد بيصرف المباريات على أزواج قريبة وunder-sampled.
Random تختار أي زوج.
Round-robin تختار الزوج الأقل لعباً، .
Ladder تقارن الجيران في الجدول الحالي.
Active تصرف المباراة الجاية وين عدم يقين الرتبة أعلى:
المنحنى هو Kendall — صحة الجدول — مقابل عدد المباريات. القيمة الأعلى أفضل؛ الترتيب الكامل يعطي 1. السياسات اللي بتصوّب على الحدود بتحسم الجدول أسرع لأنها عم تصرف الميزانية وين الترتيب لسه ممكن يتحرك.
خلّي الـ scheduler على إنت الكشّاف (اضغط 2). اختار لاعبين، اعمل مباراة، اطلع على الجدول، وقرّر مرة ثانية.
المباريات الواضحة بتحسّسك بالأمان. نادراً بتغيّر شيء.
ليش مجموعة المرشحين لازم تكون أوسع من K
كثير مرات ما بدك الترتيب كله. بدك أفضل K.
لو ، فالـ cutline هو الحد الحالي حول الرتبة 100: المكان اللي لسه مش محسوم مين يدخل المجموعة ومين يطلع منها.
الإغراء: قارن بس العناصر الموجودة حالياً في top-K. غلط، بثلاث طرق.
- عنصر فعلاً من الـ top-K بس حالياً عند K+1 ما رح ينلعب، وبالتالي ما عنده طريق يرجع.
- داخل top-K مستقرّة، المقارنات غالباً blowouts؛ خط القطع ما بيتحرك.
- إذا القمة انعزلت عن الميدان، «المركز K» بفقد مرجعه.
الحل هو حزام مرشّحين حول خط القطع. خلي كل عنصر عدم يقينه لسه بيتداخل مع المركز K موجود. ضيّق الحزام فقط لما الدليل يشطبه.
افتح الكود: active matching حول cutline
import numpy as np
def candidate_band(scores, score_se, k, z=1.96):
"""
Keep candidates whose confidence intervals overlap the current K-th item.
score_se can come from a Hessian approximation, a bootstrap, or a posterior.
"""
order = np.argsort(-scores)
cutline_item = order[k - 1]
cutline_low = scores[cutline_item] - z * score_se[cutline_item]
cutline_high = scores[cutline_item] + z * score_se[cutline_item]
lower = scores - z * score_se
upper = scores + z * score_se
band = np.flatnonzero((upper >= cutline_low) & (lower <= cutline_high))
# Keep enough local rivals even when the intervals are overconfident early on.
local = order[max(0, k - 4):min(len(scores), k + 4)]
return np.unique(np.concatenate([band, local]))
def choose_active_pair(scores, score_se, pair_games, candidates):
"""Prefer uncertain, close pairs inside the cutline candidate band."""
best_pair = None
best_value = -np.inf
for left in range(len(candidates)):
for right in range(left + 1, len(candidates)):
i, j = candidates[left], candidates[right]
# Lightweight heuristic. A full BTL fit should use uncertainty
# of the difference s_i - s_j, including covariance.
pair_se = np.sqrt(score_se[i] ** 2 + score_se[j] ** 2)
standardized_gap = abs(scores[i] - scores[j]) / (pair_se + 1e-9)
boundary_value = 1.0 / (1.0 + standardized_gap)
pair_uncertainty = 1.0 / np.sqrt(pair_games[i, j] + 1.0)
value = boundary_value * pair_uncertainty
if value > best_value:
best_value = value
best_pair = (i, j)
return best_pair
# At every round:
# band = candidate_band(elo_rating, score_se, k=100)
# i, j = choose_active_pair(elo_rating, score_se, pair_games, band)
# winner = observe_comparison(i, j)
# elo_rating = elo_update(elo_rating, i, j, winner)
الكود فوق هو المبدأ. احفظ حزام حول الـ cutline، واستعمل أي uncertainty estimate موديلك قادر يعطيه عشان تقرر مين لسه جوّا الحزام.
مع 10,000 لاعب عندك تقريباً 50 مليون زوج ممكن. Exhaustive comparison ميتة من البداية.
استعمل estimator online مثل Elo، وscheduler adaptive يركّز المقارنات حول rating المركز K. المقياس هو recall@100: قديش من top-100 الحقيقي موجود في top-100 المقدّر.
بهالإعداد الصناعي، random pairing بيحرق مباريات بعيد عن cutline. Adaptive matching بيرجع معظم top-100 بعشرات الآلاف من المباريات بدل ما يعدّ خمسين مليون زوج.
هو بيفوز لأنه بيركّز الجهد وين membership لسه مش محسومة. العدد الدقيق بيعتمد على gaps حول rank 100، ضجيج النتائج، fit الموديل، وstopping rule.
الجزء الثالث — Combinatorial semi-bandits: لما الفعل يصير slate
الفعل هلأ بيوسع.
الجزء الأول اختار arm واحدة. الجزء الثاني اختار زوج. الجزء الثالث بيختار slate.
وهذا أقرب للمنتج الحقيقي. الصفحة غالباً ما بدها عنصر واحد. بدها top 10 منتجات، 12 snippet، 20 candidate، أو صفحة recommendations.
Pairwise ranking بيعطيك global order، بس الفاتورة O(n²). مية عنصر يعني حوالي خمسة آلاف pair. مليون؟ انتهى.
الجزء الثاني خفّض الفاتورة بإنه صرف المقارنات حول cutline. الجزء الثالث يستخدم lever ثاني: اختار slate، شوف feedback على العناصر المختارة، وحدّث هدول بس.
هذا هو combinatorial semi-bandit: الفعل set، والـ feedback بيتفكك على القطع اللي اخترتها فعلاً.
لما تضطر تصنع الـ score
السياسة هي optimism مرة ثانية، بس مستوى أعلى.
اعطِ كل عنصر estimate وuncertainty bonus، وبعدين اختار top-K حسب optimistic score:
هنا هو reward estimate الحالي، و عدد مرات وصول feedback قابل للاستخدام لـ item رقم .
estimate عالي بياخذ مقعد في slate. uncertainty عالي ممكن ياخذ مقعد كمان. كل round: خذ top-K حسب ، راقب outcome لكل item مختار، وحدّث هدول items.
على surface حقيقي، additive reward assumption هشّة — position bias، cannibalization، exposure، presentation كلها بتدخل. بس الـ loop الأساسي لسه مفيد.
السؤال الصعب: من وين إجت ؟
- Reward مباشر. العالم بيعطيك رقم لكل item — click، watch time، benchmark score. وقتها السياسة تحت كافية.
- مقارنات فقط. العالم بيعطيك “A beat B”. Comb-UCB بدها reward لكل item، فـ raw pairwise wins بدها scoring layer قبلها.
بالحالة الثانية، إنت بتصنع proxy للـ reward.
اعمل tournaments صغيرة: خلي judge يرتّب 10–20 items، اكسر الترتيب لـ pairwise wins، وfit Bradley-Terry مثل الجزء الثاني. الـ tournament بحوّل مقارنات محلية لـ latent على scale مشتركة.
هذا السكور مش ground truth. هو أفضل estimate حالي تستخدمه حتى توزع جولة الحكم الجاية.
الجزء الثاني بصنع الـ score. الجزء الثالث بقرر وين تصرف slate الحكم الجاية.
افتح الكود: combinatorial UCB مع per-item rewards
import numpy as np
class CombinatorialUCB:
def __init__(self, n_items, exploration=1.0):
self.reward_sum = np.zeros(n_items)
self.pulls = np.zeros(n_items, dtype=np.int64)
self.exploration = exploration
def select_slate(self, k, t):
means = np.divide(
self.reward_sum,
self.pulls,
out=np.zeros_like(self.reward_sum),
where=self.pulls > 0,
)
bonus = np.full_like(means, np.inf)
seen = self.pulls > 0
bonus[seen] = self.exploration * np.sqrt(np.log(max(t, 2)) / self.pulls[seen])
scores = means + bonus
# argpartition avoids sorting every item when k << n_items.
slate = np.argpartition(scores, -k)[-k:]
return slate[np.argsort(-scores[slate])]
def update(self, slate, rewards):
self.pulls[slate] += 1
self.reward_sum[slate] += np.asarray(rewards)
slate = policy.select_slate(k=12, t=round_number)
rewards = observe_per_item_rewards(slate) # one reward for every selected item
policy.update(slate, rewards)
اقرأ الديمو كمقارنة بين قنوات feedback.
Comb-UCB بياخذ عدة rewards مباشرة بكل round، واحد لكل item مختار. Bradley-Terry بياخذ bit مقارنة واحد بكل duel، وبعدين بيفت ranking عالمي قابل لإعادة الاستخدام.
المثال الأساسي: نعدّن reviews لأفضل line
هلأ خذ pile حقيقي: آلاف customer reviews، وبدك تطلع كم line فعلاً noteworthy.
ما في reward طبيعي لكل snippet: لا click، ولا benchmark score، ولا scalar target نظيف. الإشارة المتاحة هي judgment.
الـ semi-bandit بقرر أي snippets تستحق judgment بعدين. Bradley-Terry بحوّل هاي الأحكام لـ score.
candidates = extract_snippets(reviews) # large pool, no scores yet
score = {c: 0.0 for c in candidates} # Bradley-Terry latent reward
pulls = {c: 0 for c in candidates}
pairs = []
for t in range(1, rounds + 1):
# 1. SELECT an optimistic, diverse slate using current BT scores
ucb = {c: score[c] + C * sqrt(log(t + 1) / (pulls[c] + 1)) for c in candidates}
slate = top_k_constrained(ucb, k=K, max_per_type=...) # <= K, capped per type
# 2. JUDGE: one listwise ranking of the slate -- a small tournament
ranking = llm_rank(slate) # "order these from best to worst"
# 3. CALIBRATE: ranking -> pairwise wins -> refit Bradley-Terry
pairs += ranking_to_pairs(ranking) # i beats j for every i ranked above j
score = fit_bradley_terry(pairs)
# 4. only judged items count as pulled
for c in slate:
pulls[c] += 1
best = sorted(candidates, key=lambda c: score[c], reverse=True)[:K]
شغلتين بتخلّي هذا يهرب من فاتورة .
UCB selectivity بيصرف الحكم وين الترتيب لسه مش محسوم، وبيترك الذيل settled.
Listwise judging بيحوّل call واحدة لقيود كثيرة: ترتيب K items يعطي pairwise wins. هاي مش observations مستقلة، بسها لسه قيود ترتيب مفيدة.
شغّلت هذا على 1,500 review حقيقي أربع وخمس نجوم: 114 candidate lines بعد filtering، ، و11 rounds.
الفاتورة اللي ما دفعها:
| exhaustive pairwise | this run | |
|---|---|---|
| candidates | 114 | 114 |
| one full pass | 6,441 pairs | not taken |
| expensive judge calls | thousands | 22 |
| pairwise constraints | — | 2,582 |
| the dull tail | compared anyway | judged 0–1× |
أطرف lines طلعت، حسب Bradley-Terry score:
| Bradley-Terry | judged | the line |
|---|---|---|
| +4.05 | 11× | "3.6 Roentgen. Not great, not terrible." |
| +3.16 | 9× | "There is a reason more people have Amazon Prime than own guns in the United States." |
| +3.09 | 8× | "Thanks Amazon — if it was up to you, I would never have to leave my house. Unfortunately there are some inconveniences in my life, such as work." |
| +2.86 | 11× | "I bought my uncle a penis enlargement book for 'Secret Santa'… Hoping this rating grows to five stars, depending on results." |
| +2.28 | 9× | "Only problem is they don't come through my door and start performing." |
| +5.22 | 1× | "…the best thing that ever happened to me. Family comes second." |
آخر row هو failure mode اللي optimism معمول عشان يمسكه.
عنده أعلى fitted score بعد حكم واحد — وهذا بخليه مثير للاهتمام، مش موثوق. UCB لازم يرجعه لاختبار ثاني بدل ما يتوّجه.
الـ line الموثوق هو اللي انحكم 11 مرة. أعلى score وأعلى score بتصدّقه سؤالين مختلفين. ranking بـ لحالها بتجاوب السؤال الغلط.
تحذير إنتاجي: optimizer بتحسّن الهدف اللي تعطيه إياه.
مرّة سابقة، بدون فلتر الأربع والخمس نجوم، طلع النظام بس outrage — جدار من قصص توصيل سيئة. الطريقة ما «اكتشفت» المضحك. هي تبعت الفلتر وتعليمات الـ judge.
noteworthy وfunny اختيارات بتشفّرها، مش خصائص optimizer بيلقاها لحاله.
Appendix: وين RUCB يدخل؟
Bradley-Terry بيعطيك scale عالمي واحد. هذا قوي، وهو افتراض.
لو التفضيلات بتعمل cycle — A بغلب B، B بغلب C، C بغلب A — القصة ذات الـ scale الواحد بتتكسر. وقتها بدك طريقة تقرأ جدول المقارنات مباشرة بدل ما تجبر كل شيء على ranking واحد.
RUCB عايش هناك: dueling bandit يحاول يلاقي Condorcet winner، عنصر بغلب كل الباقي باحتمال أكبر من 1/2، بدل ما يفترض من البداية إن في score خطّي مخفي بيرتّب الجميع.
تاريخ قصير للـ bandits
القصة ما إجت دفعة واحدة. إجت عبر تسعين سنة تقريباً، من ناس كانوا يسألوا: كيف نجرب من غير ما نضيع التجربة؟
- 1933 — Thompson. جرّب actions بنسبة احتمال إنها الأفضل. الفكرة انبعثت بعد عقود باسم Thompson sampling.
- 1952 — Robbins. صاغ trade-off بين إنك تستغل اللي باين أحسن، وإنك تدفع حتى تتعلم.
- 1952 — Bradley & Terry. score مخفي لكل عنصر، واحتمالات الفوز من فرق الـ scores.
- 1979 — Gittins. index policy أنيقة للـ Bayesian discounted bandit.
- 1985 — Lai & Robbins. حدود regret: السياسات الجيدة تدفع regret ينمو مثل .
- 2002 — Auer, Cesa-Bianchi & Fischer. UCB1 خلى optimism عملي وبضمانات finite-time.
- 2009–2012 — dueling bandits. feedback صار «A غلب B»، مش reward رقمية.
- 2010 — contextual bandits. أفضل arm صار يعتمد على context معروف قبل القرار.
- 2013 — combinatorial semi-bandits. تختار slate كاملة وتشوف reward لكل قطعة مختارة.
المنحنى العام: arm واحدة، بعدين زوج، بعدين context، بعدين slate.
شو طلع معنا؟
نفس المشكلة، قناة feedback مختلفة.
المعروف: الأفعال الممكنة.
المجهول: القيم اللي بتخلي فعل أحسن من فعل.
النادر: المشاهدات اللي بتكشف هالقيم.
لو الأفعال مستقلة، هاي multi-armed bandit. لو الـ feedback مقارنات، هاي dueling/ranking problem؛ Bradley-Terry طريقة واحدة لتحويل المقارنات لـ score مشترك. لو الفعل slate والـ feedback بيرجع لكل عنصر مختار، هاي combinatorial semi-bandit.
السطح بيتغيّر: مطعم، مباراة، slate.
بس فعلياً، إنت تختار أي جهل بستاهل تدفع لتشيله.