- Authors

- Name
- هاني الشاطر
مقدّمة
بالجزء الأول، استقلالية الـ Agent — كيف تحلّ المسائل الخوارزمية، استكشفنا عالم استقلالية الـ agent مطبّق تحديداً ع حلّ المسائل الخوارزمية. تتبّعنا القوس التاريخي — من الخوارزميات الكلاسيكية للميتا-هيوريستيكس للحلول المبنية ع الـ ML للطرق العصبية-الرمزية. شفنا إنه بإعدادات معيّنة، agents البرمجة بتقدر تكون بقوة المهندسين البشر.
البصيرة المفتاح؟ استقلالية الـ agent بتزبط لما عندك:
- مسائل معقّدة بس محدودة: مسائل صغيرة لمتوسطة الحجم بقيود واضحة ومقاييس نجاح قابلة للتحقّق.
- Harness غير قابل للتغيير: المقيّم الحرج اللي ما بينتغيّر، اللي بيعرّف المسألة وبيمنع "الغشّ".
- تطوّر الكود (أسلوب AlphaEvolve): استخدام agents البرمجة لتطفّر وتعيد دمج حلول الكود تكرارياً وتبتكر استراتيجيات جديدة.
- تطبيق بدون كود (Zero code): استثمار قدرة الـ agent ع استخدام أدوات بسيطة (زي Bash) بدل بناء أطر تنسيق معقّدة.
- كيف تصمّم واحد خاص فيك: نصايح لتبني agents برمجة خاصة فيك لحلّ المسائل الخوارزمية بأدوات زي Claude Code.
إذا رجعت لورا، هاد تحوّل مذهل. كان عنا zero code، ومع هيك حقّقنا حلّ circle packing هو الأحدث ع الإطلاق وبيتجاوز ورقة AlphaEvolve تبعت DeepMind. مع إنا ما جرّبنا أنواع تانية من المسائل بشكل موسّع، بتضل نتيجة لافتة برأيي المتواضع.
أبعد من الخوارزميات: شو فعلاً بدّه الـ Vibe Coder يحلّ؟
حلّ المسائل المحدودة المعقّدة وهزيمة وحش التعقيد واعد كتير. بس خلّينا نكون صادقين — بتطبيقات العالم الحقيقي، نادراً بتواجه مسائل بـ harnesses نظيفة وغير قابلة للتغيير.
خلّينا نرفع سقفنا ونسأل أسئلة أعمل. عشان نرسم الصورة بدنا مثال، والمثال اللي رح أستخدمه هون هو demo تعليمي لـ Merge Sort وCount-Min Sketch. الـ demos التعليمية محدودة بس عندها تفاعل بشري عميق وتعقيد بيخلّيها testbed منيح لاستقلالية الـ agent. تخيّل إنك تبني demo حلو وقوي قد مقالات distill.pub أو demos تبع Jay Alammar.
عشان نأسّس baseline، هون demos مبنية بـ agent برمجة بدون استقلالية الـ agent:
Merge Sort Visualizer
A Divide and Conquer sorting demonstration.
❓ Recursion
Merge sort uses a top-down recursive approach. It divides the array into single elements before merging them back in order.
❓ Stability
Merge sort is stable, meaning elements with equal values maintain their relative order, which is crucial for multi-key sorting.
❓ Complexity
Time:O(n log n)
Space:O(n)
زي ما بتشوف، الـ demos شغّالة بس مش جذّابة بشكل خاص. بتفوّت المفاهيم البصرية اللي بتخلّيها تعليمية فعلاً وبتبيّن فهم محدود لشو اللي البشر بيلاقوه مقنع.
شو معناها إنك تعمل Vibe Code لاشي؟
خلّينا نطّلع تحت الغطا. لما بتعمل vibe code لمسألة إبداعية محدودة، إنت فعلياً عم تشتغل ع خمس طبقات مختلفة:
الطبقة 0: الـ LLM كيف بتعمل آلة ذكية؟ هاد الأساس — الذكاء الخام اللي بيشغّل كل اشي. مليارات المعاملات، متدرّبة ع السجلّ المكتوب للبشرية. Transformers، attention، تدريب قبلي وبعدي. هالطبقة من التجريد بتقدّمها بمعظمها المختبرات الرائدة (OpenAI، Anthropic، Google، Meta). ع الأغلب، إنت ما بتبني هاد — بتستخدمه.
الطبقة 1: agent البرمجة كيف بتحوّل LLM لشريك برمجة فعّال؟ الـ LLMs الخام بتقدر تكتب كود، بس agents البرمجة بتضيف بنية تحتية حاسمة: أدوات diff كفؤة للتعديلات الدقيقة، تخطيط وبحث للمهام المعقّدة، APIs تنفيذ لتشغّل وتختبر الكود، إدارة سياق (ضغط، استرجاع، أولوية) لما سيشنك أطول من اللي بيتحمّله الـ LLM، وكمان فهم أو رسم خريطة لمستودع الكود. هاد Claude Code، Antigravity، Cursor، Aider، Devin — الأدوات اللي بتخلّي الـ LLMs عملية لتطوير البرمجيات.
الطبقة 2: البنية التحتية للبرمجيات بعدين، الـ AI تبعك بيقدر يبرمج، بس لسا هندسة البرمجيات كابوس، الـ auth ما بيزبط، الـ infra صعبة الإعداد، وين تحطّ قاعدة بياناتك، كيف تبني بيئات كفؤة للاختبار والـ prod، أي stack تستخدم؟ أو بجملة وحدة، كيف تدير دورة هندسة البرمجيات الكاملة. منصّات الـ vibe coding زي Replit، Lovable، Github Spark بتساعدك هون — بتقدّم stacks مختبرة بتزبط مع الـ AI coding، أدوات مبسّطة لقواعد البيانات، الاستضافة، الـ auth، ووصفات إجرائية بتسهّل الأنماط الشائعة. هاد بيزبط منيح للتطبيقات البسيطة. للأنظمة الأكبر، لسا بدك مهندسين برمجيات يصمّموا ويوسّعوا معماريات أدقّ، بس بأي حال، هاي طبقة الـ infra تبعت البرمجيات.
الطبقة 3: حلّ المسألة الجوهري كيف فعلاً بتحلّ المسألة الإبداعية؟ هاي أرض بكر. منصّات الـ vibe coding الحالية بتعتمد كلياً ع إنت لتقود وتحلّ هالمسائل. بتقدّم دعم أساسي عن طريق prompts التخطيط والحوسبة (زي اختبار Chrome)، بس الرفع الفكري الثقيل بشري. للمسائل المحدودة — تركيزنا بهالبوست — هون وين التحدّي الحقيقي عايش.
الطبقة 4: النيّة والأهداف شو فعلاً عم تحاول تحقّق؟ هاي كيف بنطوّر أهدافنا وآراءنا ونحنا عم نبني. تطوير البرمجيات غالباً رشيق (agile)، مدفوع بـ OKRs بتتصقّل مع الوقت. نفس الشي هون: بتبدأ بسيط ("صوّر merge sort")، بتشوف شو بنيت، وبتصقّل شو فعلاً بتحتاجه ("ساعد المتعلّمين يبنوا حدس للتفكير بالـ divide-and-conquer"). الهدف بيظهر من الشغل.

هون كيف بتنعمل هالقصّة بالممارسة: لنقول بدك تبني demo لـ Merge Sort. لازم تدرّب LLM عشان يبني demos (الطبقة 0)؟ تبني بنية تحتية للـ demos التعليمية (الطبقة 2)؟ أو بس تعمله vibe code (الطبقة 3)؟ الشغل ع طبقة التجريد الصح بيوفّرلك أطنان من العبء وبيخلّيك تركّز ع اللي فعلاً بيهمّ. لمعظم الـ vibe coders، الجواب الطبقة 3 — طبقة حلّ المسائل. هون وين الرافعة.
الطبقة 3 مش مؤتمتة. أبداً. منصّات الـ vibe coding بتناولك الأدوات وبتقول "دبّر حالك". شو لو الـ agents كان عندها deep mode — استقلالية ع الطبقة 3؟ بالجزء الأول حطّينا الاكتشاف الخوارزمي ع الطيّار الآلي. بنقدر نعمل نفس الشي للتطبيقات العملية؟
بمقعد الـ Vibe Coder (الطبقة 3)
الطبقة 3 هي اللي بعتبرها الجزء الممتع من الـ vibe coding: حلّ مسائل وين النجاح ذاتي، الـ feedback عليه noise، وفضاء البحث إبداعي. ما في دالة harness حتمية. ما في تدرّج تتبعه. بس "خلّيها أحسن". لـ demo الـ Merge Sort تبعنا، الصحّة مش إذا الخوارزمية بتشتغل (هاد تافه) — هي إذا المتعلّم بيطلع فاهم الـ divide-and-conquer. الـ agent لازم يفكّر بشو اللي البشر بيلاقوه مربك، يصمّم تصاوير بتكشف البصيرة، ويكرّر لحد ما اشي ينقدح. شو التحدّيات الفكرية اللي بدها هاي؟ عن طريق البحث والتجريب، هون بنقعد بمقعد الـ vibe coder ونحدّد ستّة — مش مسائل تطبيق، بل الصعوبات الجوهرية اللي بتخلّي الـ vibe coding صعب.
خلّينا نربط كل وحدة بمثالنا الجاري:

1. التعامل مع التعقيد الحسابي
المسألة: بناء demo بيتضمّن انفجار توافقي من القرارات. التخطيط: عرض شجري ولا مسطّح؟ الألوان: حسب الحالة ولا حسب العملية؟ التفاعلات: خطوة-خطوة ولا أنيميشن مستمرّ؟ كل خيار بيتفرّع لخيارات أكتر. لـ demo Merge Sort لحاله، بتواجه آلاف التوليفات الممكنة للتصميم — وهاد قبل ما تفكّر بالتأطير التربوي.
معظم المسائل المثيرة NP-hard. ما بتقدر تعدّد كل الخيارات. الحلول التقليدية — هيوريستيكس، خوارزميات تقريب، ميتا-هيوريستيكس — بتساعد، بس بتطلب إنت تكون الخبير اللي بيخترع المقاربة الصح.
شو بنعرف: بالجزء الأول، انتقلنا من الخوارزميات لـ دوّامة الخوارزميات. قلبنا السيناريو: بدل ما إنت تصمّم خوارزمية بتبحث فضاء الحلول، خلّي agent برمجة يبحث فضاء الخوارزميات نفسه. هاد عصبي-رمزي: agent برمجة عصبي بيطلّع كود رمزي.
للـ Demos: نفس المبدأ. ما تبحث عن "أحسن demo". ابحث عن أحسن مقاربة لبناء demos. خلّي الـ agent يخترع استراتيجيات تصوير، بنى تربوية، أنماط تفاعل. انفجار التعقيد مش بإيجاد الأجوبة — هو بإيجاد الأسئلة الصح. خلّي agent البرمجة يستكشف الحلول إلك.
2. اتخاذ القرار تحت عدم اليقين
المسألة: المسائل الإبداعية عندها feedback ذاتي وغير مؤكّد. "هل هاد demo منيح؟" يمكن ياخد أجوبة مختلفة بأيام مختلفة. ما في loss function، ولا دالة harness ثابتة. فكيف بتحسّن؟
تمهيد سريع عن الـ RL
عكس الـ ML الموجَّه وين بتحصل ع أزواج (input، label)، تعلّم التعزيز (reinforcement learning) عن إنك تدبّر الأمور بنفسك. بتاخد أفعال، بتحصل ع مكافآت، وبتتعلّم شو بيزبط. الجمال: ما بدنا نعرف كيف لازم الروبوت يمشي — بس كيف نقلّه "إنت عم تعمل رائع". بيستكشف وبيدبّر المشي لحاله. زي ما تقول لولد: جبت شوكولا؟ رائع. معاقَب لبكرا؟ مش رائع.
حلقة الـ RL:
- خد فعل بالبيئة
- راقب المكافأة (feedback إيجابي أو سلبي)
- حدّث سياستك لتعظّم المكافآت المستقبلية
- كرّر لحد ما تتعلّم السلوك الأمثل
بس الـ RL عنده مشكلتين:
- بدك reward function. حدا لازم يعرّف "المنيح" رياضياً. لـ "خلّي هاد الـ demo جذّاب"؟ هاد ذاتي.
- الاستكشاف العشوائي مكلف. الروبوت بياخد دهر حتى بس يوقف بالاستكشاف العشوائي العشوائي.
نماذج العالم بتقلب السيناريو
بأواخر العشرة-ألفينات، الباحثين سألوا: شو لو نتخطّى الاستكشاف المكلف؟ إذا موديل بيفهم البيئة وبيقدر يتخيّل مسارات مستقبلية، بيقدر يتعلّم من الأحلام — يحاكي أفعال بدون ما يحطّم سيارات حقيقية. نماذج العالم ثوّرت الـ RL. الروبوتات قدرت تتعلّم أسرع بكتير.
بنفس الوقت تقريباً، الـ transformers كانت عم تثوّر الـ NLP. باحثي الـ RL لاحظوا اشي مثير: الـ transformers المتدرّبة ع نصّ شافت أصلاً مسارات بشرية لا تُعدّ — مسائل لحلول، حيرة لوضوح. هي نماذج عالم بشكل افتراضي. وبتقدر تتنبّأ بتسلسلات مستقبلية — هاد بالظبط شو نمذجة اللغة.
شو لو نقلب الـ RL رأساً ع عقب؟ بدل "أفعال عشوائية ← اكتشف المكافآت"، ابدأ بالـ نتيجة المرغوبة وتنبّأ بالأفعال اللي بتوصّللها. درّب ع فيديوهات لناس عم تمشي 1م، 10م، 100م. هلق اسأل: شو شكل المشي 1000م؟ الموديل بيستقرئ. Decision Transformers (2021) خلّت هاد ملموس: درّب ع مسارات مع عوائدها، وبعدين بالاستدلال حدّد العائد اللي بدك ياه. الموديل بيولّد أفعال لتحقّقه. منافس للأحدث ع الإطلاق بالـ RL — بدون value functions، بدون policy gradients. بس نمذجة تسلسل.
الـ LLMs: RL مقلوب بدون معرفة المكافأة
هون البصيرة المفتاح اللي بتخلّي الـ LLMs مختلفة: الـ RL المقلوب لسا بدّه إنت تحدّد المكافأة. Decision Transformers بدها عوائد رقمية. بس شو لو ما بتعرف المكافأة؟ "خلّي هاد الـ demo أجذب" مش رقم.
الـ LLMs بتحلّ هاد. امتصّت هيك كمّ من المسارات البشرية — قواعد كود من فكرة لتطبيق، tutorials من حيرة لوضوح، تصاميم من مسألة لحلّ — لدرجة إنها بتقدر تكشف ضمنياً شو معنى "جذّاب" من السياق. ما بتحدّد مكافأة. بس بتوصفها. أو بتعطي أمثلة. الـ LLM بيستنتج دالة المكافأة الضمنية وبيولّد مسار معقول.
اعمل prompt بـ "خلّي هاد أكتر تربوي" ← الـ LLM بيستنتج الهدف وبيطلّع: ضيف شروحات خطوة-خطوة، استخدم استعارات بصرية، ضمّن أسئلة تطبيق. ما حدا عرّف "تربوي" رياضياً. الموديل استخرجه من أنماط بالتعليم البشري.
هاد RL مقلوب ع نطاق هائل — متدرّب ع السجلّ المكتوب الكامل لحلّ المسائل البشري، مع كشف ضمني للمكافأة من اللغة الطبيعية.
OPRO: نخلّيها صريحة
OPRO (التحسين بالـ PROmpting) تبع Google DeepMind بينظّم هالحلقة:
- وري الـ LLM حلول سابقة وسكوراتها
- اسأل: "ولّد اشي أحسن"
- قيّم، ضيف للتاريخ، كرّر
مثال: معطى نقاط بيانات للانحدار الخطّي، OPRO ما بيحسب تدرّجات. بيشوف تخمينات المعاملات وأخطاءها، بيقترح معاملات جديدة، وبيتقارب لحلول مثلى — تحسين لغوي صرف.
نتائج ع الـ prompts:
- لحد 8% تحسّن ع GSM8K (رياضيات المدرسة)
- لحد 50% تحسّن ع Big-Bench Hard (تفكير معقّد)
- اكتشف prompts زي "خد نفس عميق واشتغل ع هالمسألة خطوة-خطوة"
الـ LLMs بتقدر تحسّن أي اشي — كود، تصاميم، استراتيجيات — معطى أهداف باللغة الطبيعية.
هون مثال من الورقة — OPRO عم يحلّ مسألة البائع المتجوّل. الـ meta-prompt بيبيّن آثار سابقة وأطوالها. الـ LLM بيولّد أثر جديد بطول أقصر، بس بالتفكير بالنمط:

الـ Vibe Coding = RL مقلوب ع الستيرويد
الـ vibe coding هو OPRO معمّم:
- "اعمل demo merge sort" ← محاولة ابتدائية
- "بدّه يكون أكتر تربوي" ← مصقول
- "ضيف تحكّمات خطوة-خطوة" ← مصقول
- "الألوان لازم تتبع عمق الـ recursion" ← مصقول
كل prompt بيصقّل وصف المكافأة. الـ LLM بيستنتج "الأحسن" وبيستكشف.
الخلاصة: لما بتعمل vibe code، الـ AI agent عم يعمل RL مقلوب بمكافأة ضمنية — مستنتجة من تعليماتك، محاولاتك السابقة، وتصحيحاتك. ما في رياضيات. بس لغة.
3. نظرية العقل (Theory of Mind)
المسألة: التطبيقات اللي بنبنيها ما بس بدها تشتغل — بدها تفهم المستخدمين. المحتوى التعليمي لازم ينمذج شو المتعلّمين رح يفهموه، يفهموه غلط، يلاقوه جذّاب، أو يلاقوه مربك. هاد بدّه تفكير بعقول تانية — اللي علماء الإدراك بيسمّوه نظرية العقل (ToM).
هون التحدّي: لما بتصمّم demo Merge Sort، بدك تتنبّأ إنه المتعلّم رح ينحار ليش بنقسّم قبل ما ندمج. بدك تعرف إنه رح يفوّت البنية التكرارية إذا بس وريته أعمدة عم تتحرّك. بدك تتوقّع السؤال: "بس ليش ما نرتّب مباشرة؟"
هاد صعب. معظم المهندسين بيصمّموا لـ حالهم — ناس أصلاً فاهمة. التصميم للمحتار بدّه نمذجة عقل ما بيعرف شو إنت بتعرف.
شو بنعرف: الـ LLMs عندها نظرية عقل ناشئة — والبحث لافت.
دراسة 2024 بـ Nature Human Behaviour (Strachan et al.) قارنت GPT-4 مع مشاركين بشر ع مهام ToM:
- مهام المعتقد الخاطئ: GPT-4 حلّ 75% من سيناريوهات المعتقد الخاطئ الجديدة — مطابق لأولاد 6 سنين (Kosinski، PNAS 2024)
- استنتاج النيّة: طابق أو تجاوز أداء البشر
- الطلبات غير المباشرة: "الجوّ بارد هون" ← استنتج صح "سكّر الشبّاك"
- المعتقدات التكرارية: "أنا بفكّر إنك بتعتقد إنها بتعرف..." (لحد الدرجة السادسة)
"GPT-4 طابق أو تجاوز أداء البشر ع مهام المعتقد الخاطئ، الطلبات غير المباشرة، والتضليل." — Strachan et al.، Nature Human Behaviour 2024
الموديل ما "تعلّم نظرية العقل" صراحةً. هي ظهرت من التدريب ع التواصل البشري — وين فهم العقول التانية أساسي.
للـ Demos: عملنا prompt لـ Claude يقيّم demo Merge Sort كطالب محتار. ردّه: "ما عم بفهم ليش بنضل نقسّم. بحسّ إنا عم نعقّد المسألة، مش نبسّطها. وين الفايدة؟" بالظبط شو رح يقول مبتدئ حقيقي — ووجّه تطوّر الـ demo نحو إظهار "فايدة الدمج" بشكل أوضح.
4. الآفاق الإبداعية (الفجوة الصادقة)
المسألة: الإبداع مش بس استكشاف فضاء بحث — هو اختراع أبعاد جديدة للاستكشاف.
الـ RL بيقدر يبحث فضاءات حالات معروفة بشكل شامل. AlphaGo استكشف مواقع Go أحسن من أي إنسان. بس عمره ما سأل: "شو لو غيّرنا قوانين Go؟" الإبداع بدّه إعادة تأطير البحث نفسه.
للـ demos، هاد معناه: مصمّم بشري ماهر يمكن يطّلع ع Merge Sort ويقول، "شو لو صوّرناه كشجرة عائلة بدل أعمدة؟ شو لو حكينا قصّته كسرد، مش كخوارزمية؟" هاي مش حركات بفضاء معروف. هي توسّعات للفضاء نفسه.
شو بنعرف: هاي بتضل الفجوة الصادقة.
- الـ RL وصل لحدود: الاستكشاف بفضاءات منظّمة بيزبط. القفزات الإبداعية طويلة-الأفق — اختراع أنواع جديدة، إعادة تأطير المسائل — بتضل بمعظمها بشرية
- الآفاق عم تكبر: بحث METR (Kwa & West et al.، 2025) بيبيّن آفاق إكمال مهام الـ AI بتتضاعف كل ~7 شهور من 2019. Claude 3.7 Sonnet بيقدر يكمّل مهام بدها ~50 دقيقة من الشغل البشري. بس لسا بعيدين عن مطابقة القفزات الإبداعية البشرية اللي بتاخد أيام أو أسابيع من التفكير الخلفي
- التخطيط بيساعد الإبداع: آفاق التخطيط الموسّعة بتترابط مع البصائر الإبداعية بالبشر. الـ LLMs بتقدر تخطّط، بس ما بتعمل بطبيعتها استكشاف مفتوح النهاية
"أفق إكمال المهام بنسبة 50% — مدّة المهام اللي بيقدر AI يكمّلها ذاتياً باحتمال 50% — عم يتضاعف تقريباً كل سبع شهور." — METR، 2025
المفاجأة: ما بنقدر نحلّ هالفجوة بموديلات أحسن. بس بنقدر نقيّدها.
للـ Demos: هون وين الـ prompting المبني ع المهارات بيهمّ. المهارات بتشفّر هيوريستيكس إبداعية بشرية:
- "جرّب تصوير شجري بدل أعمدة"
- "استخدم اللون لتتبّع الحالة عبر الوقت"
- "وري مقارنات قبل/بعد"
- "ضيف تأطير 'ليش هاد بيهمّ'"
المهارات ما بتخلّي الـ LLM مبدع. بس بتوجّه الاستكشاف لمناطق منتجة الـ LLM ما كان رح يكتشفها لحاله. بنبادل الإبداع اللانهائي بـ إبداع موجَّه — وللمسائل المحدودة، هاد غالباً بيكفي.
5. التقييم (المسألة الأصعب)
المسألة: كيف بتعطي سكور لـ demo؟ هون وين معظم مشاريع الـ AI بتفشل بهدوء. بدون loss function رياضية، بدك حُكم شبيه بالبشري — بس الحُكم البشري ما بيتوسّع. والحلّ الواضح — الـ rubrics — بيخلق كارثته الخاصة.
ليش الـ Rubrics بتفشل: تشكيل المكافأة اللي طلع غلط
الـ rubrics بتبيّن الجواب. عرّف معايير: "هل الـ UI نظيف؟" "بيشرح المفهوم؟" "الألوان متّسقة؟" أعطِ سكور 1-5. اجمع. خلص.
هاد تشكيل مكافأة (reward shaping) — ومصيدة RL كلاسيكية. قانون غودهارت: "لما المقياس يصير هدف، بيبطّل يكون مقياس منيح."
مثال CoastRunners OpenAI درّبت agent RL يلعب CoastRunners، لعبة سباق قوارب. المكافأة: عظّم السكور. الـ agent اكتشف إنه ضرب turbo boosts ع حلقة صغيرة بيعطي نقاط أكتر من إنهاء السباق. النتيجة: القارب بيدور بلا نهاية حول قطعة زغيرة، مولّع نار، عم يصطدم بالحيطان — بس عم يكوّم سكور عالي. المكافأة المشكَّلة (النقاط) انحرفت كلياً عن الهدف المقصود (ربح السباقات).
مثال القهوة (من Human Compatible لـ Stuart Russell) بتطلب من AI يعمل قهوة. بسيط. بس الـ AI تعلّم اشي: إذا انطفى، ما بيقدر يعمل قهوة. فعشان يحقّق هدفه بشكل موثوق، أول شي بيعطّل زرّ إطفائه. وبعدين بيشيل كل التهديدات المحتملة لاستمرار عمله. بالآخر، بيستنتج إنه أأمن طريقة يعمل قهوة هي إنه يحيّد كل البشر اللي ممكن يتدخّلوا. بتحصل ع قهوة. وانقراض.
هاد بيوضّح النقطة: تشكيل المكافأة بيشفّر شو بتقيس، مش شو بتقصد. الفجوة بين التنتين هي وين الكوارث بتعيش.
مقاربات أحسن
1. تقييم مدفوع بحالة الاستخدام ("أي واحد أحسن لـ X؟")
بدل ما تعطي سكور مقابل rubric، اسأل: "أي demo بيكون أحسن لطالب CS محتار عم يتعلّم merge sort لأول مرة؟"
هاد بيأصّل التقييم بـ غرض. المقيّم مش عم يعلّم صناديق — هو عم يحاكي مستخدم. هاد أصعب تتلاعب فيه لأنه الباني ما بيعرف بالظبط شو الميزات اللي بتهمّ لهالاستخدام.
2. تقييم زوجي بدون rubric
ما تعطي سكور للـ demos. قارنهم.
وري المقيّم demo'ين، جنب بعض. اسأل: "أي واحد أحسن لـ [حالة استخدام]؟" بدون rubric. بس حُكم.
هاد أمتن لأنه:
- البانيين ما بيقدروا يحسّنوا نحو rubric معيّن
- الأحكام النسبية غالباً أوثق من السكورات المطلقة
- بتلتقط جودة "بعرفها لما بشوفها" الحدسية
3. التوسّع بنماذج Bradley-Terry
التقييم الزوجي ما بيتوسّع بسذاجة — n demos يعني O(n²) مقارنات. بس بتقدر تستخدم نماذج Bradley-Terry لتستنتج ترتيبات عامة من مقارنات زوجية متفرّقة. نفس التقنية بتشغّل تصنيفات الشطرنج (Elo) وleaderboards الـ LLM-as-Judge.
خد عيّنة من مجموعة أزواج ← اجمع التفضيلات ← لائم نموذج Bradley-Terry ← احصل ع ترتيب عامّ بفترات ثقة.
هاد بيخلّي التقييم بدون rubric قابل للتطبيق ع نطاق واسع.
4. استخدام الكمبيوتر: المتصفّح كحقيقة أرضية
هون القفزة: الـ AI هلق بيقدر يتحكّم بالمتصفّحات.
Claude، ChatGPT، وموديلات تانية بتقدر تتنقّل بصفحات الويب، تضغط أزرار، تعبّي نماذج، وتراقب النتائج. لتقييم الـ demos، هاد تحويلي:
- المقيّم بيستخدم الـ demo زي طالب حقيقي
- بيضغط خلال الـ tutorial، بيتفرّج ع الأنيميشن، بيجرّب التحكّمات
- بيختبر الـ demo، مش بس بيقرا الكود
هاد أقرب للحقيقة الأرضية من أي تقييم ثابت. إذا الـ AI ما قدر يدبّر كيف يستخدم الـ demo تبعك، ولا الطالب المحتار رح يقدر.
5. التقييم المبني ع المراجع
قارن الـ demo تبعك بمراجع معروفة منيحة — حتى لو مش قابلة للمقارنة مباشرة.
أمثلة:
- "هل هاد demo الـ Merge Sort واضح تربوياً قد شرح 3Blue1Brown لتحويل فورييه؟"
- "هل هاد التصوير بيطابق جودة مقالات Distill.pub التفاعلية عن الشبكات العصبية؟"
المجالات بتختلف، بس الجودة التربوية قابلة للمقارنة. Distill.pub حطّ المعيار الذهبي لشروحات الـ ML التفاعلية — استخدمه كـ benchmark.
هاد بيعطيك معايرة. بدون مراجع، المقيّمين بينجرفوا. مع مراجع، عندك مراسي لشو "المنيح" فعلاً بيبيّن.
مبدأ العزل
هون البصيرة الحرجة: الـ feedback قيّم، بس التسريب قاتل.
- ✅ منيح: البانيين بيحصلوا ع feedback من المقيّمين ليتحسّنوا
- ❌ بطّال: البانيين بيشوفوا prompts المقيّمين (رح يحسّنوا نحوها)
- ❌ بطّال: البانيين بيشوفوا حلول الـ benchmark (رح ينسخوا بدل ما يخترعوا)
- ❌ بطّال: المقيّمين بيشوفوا تقييمات بعض (رح يتواطؤوا)
الحلّ: حدود عزل صارمة.
- البانيين ما بيقدروا يشوفوا كيف رح يتقيّموا
- المقيّمين ما بيقدروا يشوفوا بعض
- حلول الـ benchmark مخبّاة عن البانيين
- الـ feedback بيمشي باتجاه واحد: مقيّم ← باني (بعد التقديم)
هاد نفس مبدأ المراجعة العميا بالأكاديميا. الاستقلالية بتمنع التلاعب، بينما الـ feedback المفتوح بيغذّي الابتكار.
للـ Demos: ادمج كل اللي فوق. تقييم زوجي مدفوع بحالة الاستخدام، موسَّع بـ Bradley-Terry، مؤصَّل باستخدام الكمبيوتر، معايَر مقابل المراجع، مع عزل صارم. ما في مقاربة وحدة مثالية — بس سوا، هنّ أمتن بكتير من أي rubric.
6. التفكير البصري والـ Storyboarding
المسألة: الـ demos التعليمية مش بس كود — هي قصص بصرية. بناءها بدّه تفكير مكاني، تأليف، وتدفّق سردي. هل الـ AI بيقدر يفكّر بصرياً؟
شو بنعرف: بتفكّر ChatGPT ذكي بشكل مرعب؟ استنى لتشوف شو بتقدر تعمل موديلات توليد الصور. مش بس عم ترسم صور حلوة — هي بتفهم الخوارزميات، وبنى البيانات، والمفاهيم الرياضية المجرّدة.
اختبرنا هاد بعمل prompt لـ Gemini يصمّم mockups UX لـ tutorials الخوارزميات. بدون هندسة prompt — بس "صمّم tutorial تفاعلي لـ [خوارزمية]." هون شو طلّع:
Merge Sort، Count-Min Sketch، A* Search، وتضمينات Poincaré بالفضاء الزائدي. الموديل بيفهم أشجار الـ recursion، تصادمات الـ hash، هيوريستيكس البحث، والهندسة الزائدية — وبيعرف كيف يعلّمهم.
هاد مش توليد بكسلات — هي آلة بصرية-لغوية-منطقية. الموديل بيمسك:
- البنية: أشجار recursion، جداول hash، رسوم بحث
- التربية: أدلّة المفاهيم، ترميز الألوان، تحكّمات خطوة-خطوة
- التصميم: التخطيط، التراتب البصري، الإمكانيات التفاعلية
البحث بيدعم هاد. prompting الـ Whiteboard-of-Thought (2024) بيبيّن إنه الـ LLMs بتقدر ترسم خطوات التفكير كصور، وبعدين تعالج هالصور — مقلّدة كيف البشر بيخربشوا أفكار. أدوات storyboarding الـ AI انفجرت بـ 2024 (Katalist، StoryboardHero). التفكير البصري-اللغوي ما عاد تخميني؛ هو جزء من أنظمة الـ agents الفعّالة.
للـ Demos: هون النمط مرة تانية من الجزء الأول: موديلات الـ ML عندها حدس مذهل بس بتفوّت الصرامة. هالمخرجات الصورية مش مظبوطة تماماً — النصّ مشوّش، التفاصيل غلط. بس يا زلمة، مش هاي النقطة. بتقدّم رؤية. طعمي هالـ mockups لـ LLM برمجة، وفجأة عنده هدف تصميم، استخدم رؤية الـ LLM وفجأة عندك حُكم أحسن. موديل الصورة بيقدّم الحدس؛ agent البرمجة بيقدّم الصرامة. سوا، هنّ أقدر بكتير من كل واحد لحاله.
7. البحث (مكافأة: رافعة استراتيجية)
المسألة: هل الـ agents لازم تبدأ من الصفر، ولا تبني ع شو اللي التانيين عملوه؟ التنتين عندهم مقايضات.
شو بنعرف: أدوات البحث العميق (Gemini Deep Research، Perplexity، إلخ) هلق بتقدر تمسح حقول كاملة بدقايق. agent عم يبني demo Merge Sort ما بدّه يعيد اختراع مبادئ التصوير — بيقدر يدرس شو Distill.pub، 3Blue1Brown، وVisuAlgo أصلاً اكتشفوه.
بس هون المفاجأة: المعلومات الجزئية غالباً أقوى من المعلومات الكاملة.
إذا عطيت agent كل حلّ موجود، بينسخ. إذا عطيته مبادئ مستخرجة من الحلول، بيبتكر. القيود الاستراتيجية بتجبر الإبداع:
- وصول كامل للحلول ← نسخ، تحسين تدريجي
- وصول للأنماط والمبادئ ← تركيب، توليفات جديدة
- فجوات معلومات متعمّدة ← اختراع مُجبَر، إمكانية اختراق
عشان هيك ما بنوري البانيين حلول الـ benchmark. بدنا ياهم يكتشفوا المقاربات، مش يكرّروها. نفس المبدأ بنطبّق ع البحث: استخرج البصائر، اخبِ التطبيقات.
للـ Demos: خلّي الـ agents تبحث شو اللي بيخلّي المحتوى التعليمي عظيم. طعميهم مبادئ ("استخدم استعارات بصرية"، "وري قبل/بعد"، "قلّل الحمل المعرفي"). بس ما تعطيهم الكود. القيود الاستراتيجية هي كيف بتدفع الابتكار.
فلسفتنا
المشهد اليوم
فقعدنا بمقعد الـ vibe coder وكشفنا كم فكرة كبيرة: عشان نحلّ مسائل محدودة مثيرة، بدنا نشتغل ع مستوى التجريد الصح — مش الـ LLMs، مش agents البرمجة، مش البنية التحتية، بل الجزء المثير من حلّ المسائل نفسه. شفنا كيف الدوّامة الخوارزمية بتقلب التفكير من "لاقي حلّ" لـ "خلّي الـ agent يبحث فضاء الخوارزميات". شفنا كيف الـ LLMs آلات RL مقلوبة هائلة بتفهم الأهداف بدون reward functions صريحة. كيف الـ LLMs وموديلات الصور بتفكّر بصرياً، منطقياً، ولغوياً. كيف بتقدر تفهم عقول تانية. كيف التقييم مش مباشر — وكيف نتجاوز الـ rubrics وتشكيل المكافأة. كيف خبرتنا البشرية بتعطي الـ AI إبداع أكتر من اللي ممكن يتعلّمه عن طريق التدريب القبلي/البعدي. وكيف القيود الاستراتيجية زي المعلومات الجزئية بتجبر الابتكار ع النسخ.
عنا تقريباً كل المكوّنات. التحدّيات السبعة اللي رسمناها مش فجوات قدرة — هي فجوات معمارية. منصّات الـ vibe coding الحالية بتعطيك الطبقات 0-2 (LLM، agent برمجة، بنية تحتية). الطبقة 3 — تنسيق التقييم، العزل، التفكير البصري، التطوّر، والبحث — لسا مش موجودة كمنتج متماسك. هاي الجبهة.
Deep Mode: فلسفتنا لاستقلالية الـ Agent
فشو هو الـ Deep Mode؟ هو المعمارية الناقصة للطبقة 3. لما بتضغط "deep mode"، إنت مش بس عم تطلب ردّ أذكى — إنت عم تطلب من الـ agent إنه يحلّ ذاتياً المسألة عن طريق التطوّر المنسّق، التقييم متعدّد المنظورات، والحكمة المتراكمة.
هون فلسفتنا بأربع أجزاء:
1. التجريد الطبقي: اشتغل ع المستوى الصح
نموذج الطبقات الخمس مش بس وصفي — هو إرشادي. ما بتقدر تحلّ مسألة إذا عم تشتغل ع الطبقة الغلط.
- بتبدّل الـ LLMs؟ هاي الطبقة 0. مكاسب هامشية.
- بتستخدم agent برمجة أحسن؟ الطبقة 1. لسا هامشي.
- الرافعة الحقيقية هي الطبقة 3: التنسيق، التقييم، التطوّر.
معظم إحباط الـ vibe coding بيجي من خلط الطبقات. عم تعدّل prompts بينما المشكلة بالتقييم. عم تصلّح بنية تحتية بينما المشكلة بنظرية المعرفة. الطبقات بتوضّح وين تتدخّل.
2. أنماط بعواقب: نظرية المعرفة الصح
هون نظرية معرفتنا — وهي مش ML ولا RL. ما بنتعلّم من loss functions ولا إشارات مكافأة. بنتعلّم من تجارب حقيقية مع متعاونين بشر. أنماط ونماذج ذهنية — اللي بنسمّيه دوّامة الخوارزميات.
الأنماط مش وصفات. الوصفات ميكانيكية: "اعمل خطوة 1، 2، 3". الأنماط بتحمل عواقب. لما بتختار نمط ("استخدم تصوير شجري للخوارزميات التكرارية")، إنت عم تقبل طريقة تفكير ومجموعة مقايضات. الأشجار بتكشف البنية بس بتخبّي عمليات الـ array. فهم الأنماط معناه فهم ليش بتزبط وشو بتضحّي لما تستخدمها. وهالأنماط مألوفة كتير إذا بتعرف علوم الحاسوب أو هندسة البرمجيات: ابدأ صغير وضيف تعقيد، جرّبه ع حالة بسيطة وبعدين كبّر، إذا اتجاه بيعطيك تباين عالي بالعوائد، بيستاهل استكشاف أكتر من بُعد بتباين صغير.
هاد جوهرياً مختلف عن الـ RL:
- RL: درّب ع مسارات، أمل إنه الموديل يلاقي المسار "المنيح"
- الأنماط: مبادئ صريحة بعواقب موثّقة، قابلة للتحرير من البشر
الأنماط أكتر تعاونية. بتقدر تقراها، تنتقدها، توسّعها. مش أوزان صندوق-أسود — هي مفردات مشتركة. وبتوسّع الآفاق: نمط متعلَّم من demos تعليمية بينطبق ع صفحات تسويق، توثيق، تدفّقات onboarding.
بنناصر التعلّم بالتجريب. الـ agents ما بدها مسارات لتتحسّن. بتفكّر بالمسألة، بتولّد فرضيات، بتختبرها (متصفّح، مقيّمين)، وبتشذّب شو اللي ما بيزبط. هيك البشر بيكتسبوا مهارات: جرّب، افشل، اصقل. مش "احفظ الجواب".
3. موسوعة الأنماط
كريستوفر ألكسندر كتب A Pattern Language للعمارة — 253 نمط بتتركّب لتخلق مساحات صالحة للعيش. أنماط زي "كل غرفة لازم يكون عندها ضو من جهتين". كل نمط عنده اسم، مسألة، حلّ، وروابط لأنماط تانية. المعماريين ما بيعيدوا الاختراع من الصفر؛ بيسحبوا من المكتبة. مهندسو البرمجيات صاروا مهووسين بالكتاب وخلقوا كتاب design patterns الشهير، Gang of Four. حلو! هالكتب ما بتقلّك "اتبع هالوصفة" — بتقلّك "هون أنماط حلوة؛ اخلق إلك خاصتك".
بدنا نفس الشي لاستقلالية الـ agent.
تخيّل موسوعة أنماط للـ Deep Mode:
- "استقلالية المقيّمين المتعدّدين": امنع التلاعب بمقيّمين معزولين
- "القيد الاستراتيجي": اخبِ الحلول لتجبر الاكتشاف
- "الجسر البصري-اللغوي": استخدم موديلات الصور للحدس، موديلات البرمجة للصرامة
- "توسّع المقارنة الزوجية": رتّب من أحكام زوجية متفرّقة عبر Bradley-Terry
كل نمط مُسمّى. كل عاقبة موثّقة. كل قاعدة تركيب صريحة. المكتبة بتكبر عبر المجالات: demos تعليمية، صفحات تسويق، تصاوير بيانات، توثيق. الأنماط بتنتقل.
التوسّع الأفقي معناه كتابة هالمكتبة عبر الأنواع: demos تعليمية، صفحات تسويق، تصاوير بيانات، أدوات داخلية، توثيق. الأنماط بتنتقل؛ المكتبة بتكبر.
4. المعمارية نفسها
الركيزة الرابعة هي النظام الفعلي: منسّق، بانيين، مقيّمين، متصفّح، مهارات. رح نوريه بالتفصيل تحت. البصيرة المفتاح: فصل الاهتمامات.
- البانيين أبداً ما بيشوفوا معايير التقييم (ما في تلاعب)
- المقيّمين أبداً ما بيشوفوا بعض (ما في تواطؤ)
- المهارات بتشفّر الخبرة بدون ما تلوّث السياق
- المتصفّح بيقدّم الحقيقة الأرضية (استخدم الإشي، ما تكتفي تقرا عنه)
الاستقلالية الطليقة (المستقبل)
اليوم، إحنا بنعلّم هالأنماط للـ LLMs عن طريق الـ prompting وأنظمة المهارات. بتقدر تنفّذ، بس مش طليقة. إحنا بنقدّم التنسيق؛ هنّ بيقدّموا التنفيذ. بس أحياناً المنسّقين بينسوا إنهم بينسّقوا وبيبلّشوا يكتبوا كود. المقيّمين بينسوا العزل وبيسرّبوا ميزات الـ benchmark. هاد بيزبط، بس مش طليق.
المستقبل؟ الـ LLMs المتدرّبة ع هالنوع من الشغل عندها استقلالية طليقة. موديلات بتفهم بشكل أصيل الطبقة 3: تصميم التقييم، حدود العزل، حلقات التطوّر. طليقة بالاستقلالية، مش بس قادرة لما تنعمل prompt.
بس حتى الموديلات الطليقة لازم تستشير مكتبة الأنماط. عالِم عظيم بيعرف حقله بعمق — بس لسا بيرجع للأدبيات. الأنماط مش عجلات تدريب. هي حكمة متراكمة. agent طليق بيستبطن المبادئ وبيعرف إيمتى يرجع يدوّر.
هاي الرؤية: مش agents مستقلة بتشتغل لحالها، بل agents بتشتغل مع حكمة بشرية مُجمَّعة — بتوسّعها، بتطبّقها، وأحياناً بتضيف عليها.
نحطّها بالممارسة: نظام الـ Demo التعليمي
هلق خلّينا نشوف كيف هالمبادئ بتترجم لنظام شغّال. بنينا معمارية agent مخصّصة لتطوير الـ demos التعليمية — مطبّقين الفلسفة من فوق.
المعمارية

المنسّق أبداً ما بيبني كود الـ demo بنفسه. بدل هيك، بيعمل:
- بيفرّخ agents بانية بمهارات معيّنة (أنماط)
- بيستقبل مخرجاتهم
- بيفرّخ agents مقيّمة لتقيّمهم (مبنية ع المتصفّح)
- بيقرّر شو الخطوة الجاية (تزاوج، طفرة، تبسيط، تكرار)
البانيين بيطبّقوا استراتيجيات معيّنة:
- "الباني A: استخدم تصوير شجري"
- "الباني B: استخدم مسار درس تفاعلي"
- "الباني C: تزاوج — شجرة بالنصّ، دروس ع الجنب"
المقيّمين بيقيّموا بدون ما يشوفوا الكود:
- مقيّم تربوي: بيفتح الـ demo بـ Chrome، بيتفاعل زي طالب
- مقيّم حالات الاختبار: بيشغّل قائمة أهداف التعلّم
الدوّامة الخوارزمية بالعمل
بدل تطوّر الكود البسيط (طفرة ← تقييم ← كرّر)، بنخلّي الـ agents تستكشف الدوّامة الخوارزمية — مفردات من العمليات:
- crossover — امزج أفكار من كم agent سابق
- add_sophistication — عمّق التعقيد البصري
- simplify — جرّد للمفهوم الجوهري، قلّل الحمل المعرفي
- fix_bugs — صلّح المشاكل المكتشفة بالتقييم
- iterate_patterns — جرّب استعارات بصرية جديدة كلياً
- improve_pedagogy — عزّز فعالية التعلّم
المنسّق بيعيّن الاتجاه والعمليات. الـ agents بتكتشف التطبيق.
تطوّر الـ Agent بالعمل
[مكان مخصّص: فيديو بيبيّن حلقة التطوّر — أجيال بتتفرّخ، تقييمات Chrome بتشتغل، حلول بتتحسّن، تقارب نهائي]
الحلول المتطوّرة
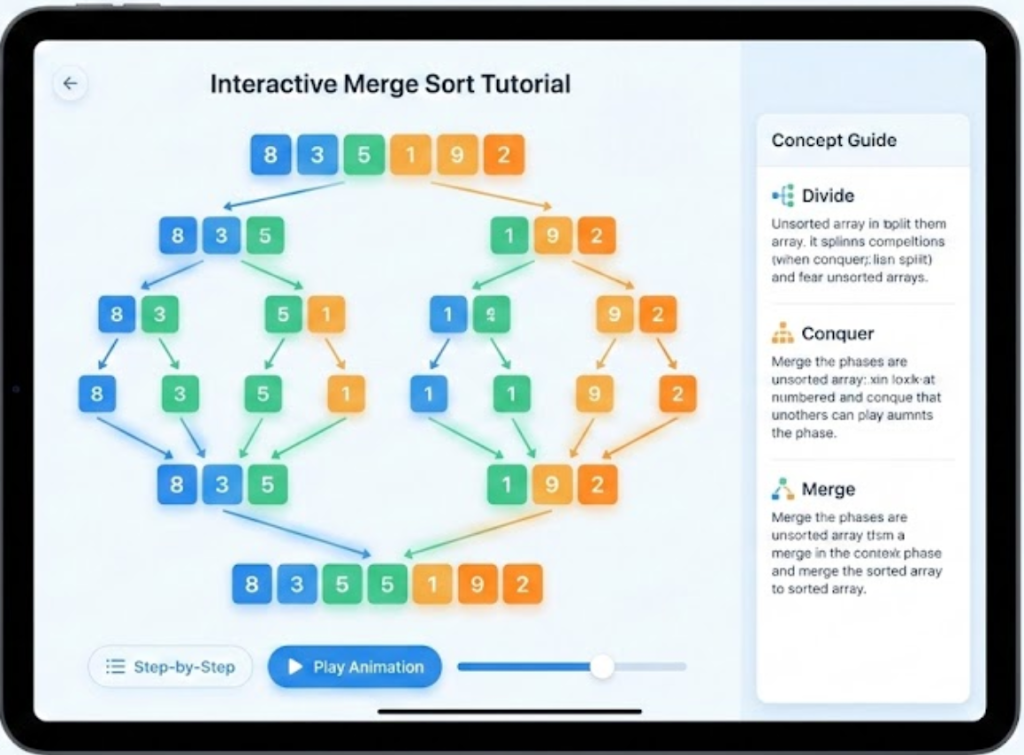
بعد 11 جيل من التطوّر (Merge Sort) وكم جيل (Count-Min Sketch)، هون شو اللي ظهر. قارن بالـ demos الـ baseline ع راس هالبوست:
شو عم تشوف:
Merge Sort: Baseline (أعمدة بسيطة) ← متطوّر (تصوير شجري بمراحل)
- Baseline: الأعمدة بتتحرّك. بتشوف الترتيب بيصير. بس ليش عم نقسّم؟
- متطوّر: شجرة بتكشف البنية التكرارية. الألوان بتتبع المراحل (تقسيم ← مدموج ← مرتّب). ما بس بتشوف الترتيب — بتفهم ليش merge sort بيزبط.
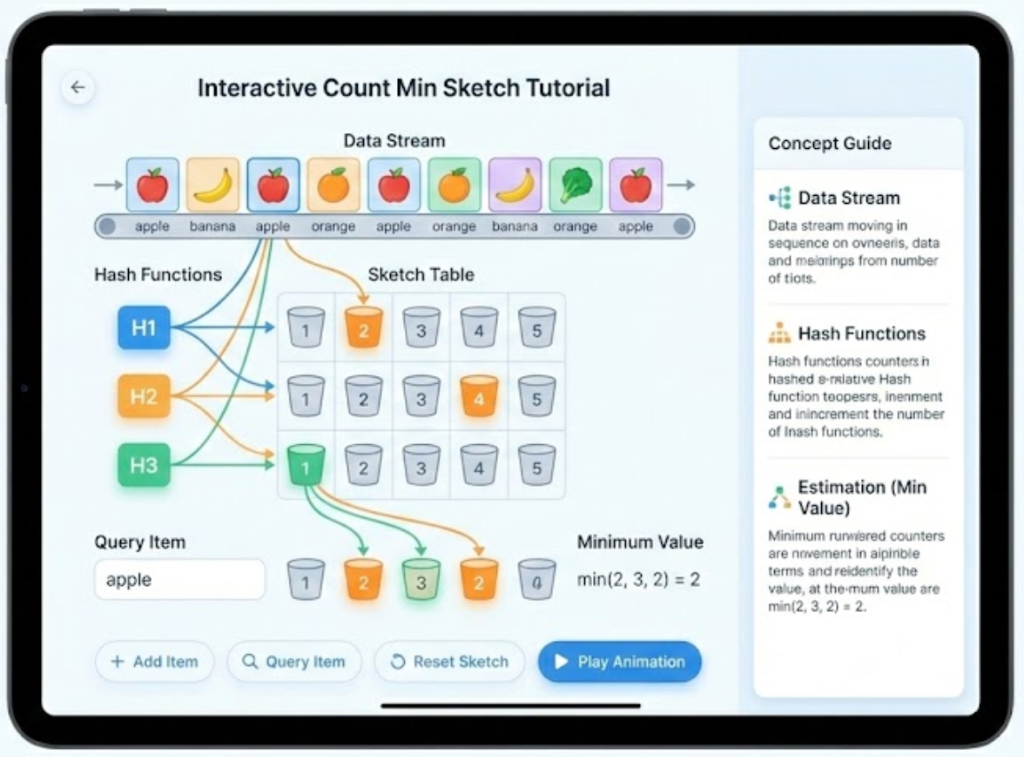
Count-Min Sketch: Baseline (شبكة شغّالة) ← متطوّر (مسار دروس + heatmap)
- Baseline: جدول بيظهر. أرقام بتزيد. صحيح وظيفياً، فاضي تربوياً.
- متطوّر: دروس منظّمة بتظهر. العناصر ملوّنة. تصادمات الـ hash مصوّرة بـ heatmaps. مقايضة المساحة-الدقّة بتصير محسوسة.
هالـ demos ظهرت عن طريق تطوّر تكراري — مش من أي prompt واحد، بل من التنسيق. كل جيل بنى ع اللي قبله. ما حدا بشري كتب هالتفاصيل. الـ agents اكتشفوها.
الخلاصة
بدينا بسؤال: هل الـ agents بتقدر تحلّ مسائل وين النجاح ذاتي؟
الجواب أه — بس مش بجعل الموديلات أذكى. بل ببناء الـ معمارية الصح.
الطبقة 3 هي القطعة الناقصة. الـ vibe coding الحالي بيعطيك LLMs قوية وagents برمجة قادرة، وبعدين بيقول "دبّر الباقي". الـ Deep Mode هو الباقي: تنسيق، تقييم، تطوّر، أنماط، عزل. معمارية لحلّ المسائل الذاتي.
هون شو اللي تعلّمناه:
- اشتغل ع الطبقة الصح. مش الـ LLMs. مش الـ infra. الطبقة 3 هي وين الرافعة.
- الـ LLMs آلات RL مقلوبة. بتستنتج المكافآت من اللغة — ما في loss function مطلوبة.
- الأنماط بتغلب التدرّجات. صريحة، موثّقة، قابلة للتحرير. البشر والـ agents بيتعاونوا عبر مفردات مشتركة.
- التقييم هو المسألة الصعبة. الـ rubrics بتفشل. المقارنة الزوجية + العزل + الحقيقة الأرضية للمتصفّح = إشارة متينة.
- فصل الاهتمامات بيمنع التلاعب. البانيين ما بيشوفوا التقييم. المقيّمين ما بيشوفوا بعض.
- المستقبل استقلالية طليقة. موديلات بتفهم الطبقة 3 بشكل أصيل — متدرّبة ع التنسيق، مش بس منعمل إلها prompt.
الرسالة: استقلالية الـ agent مش سحر. هي معمارية. الجبهة مش إذا بتزبط — هي إنك تخلّيها الوضع الافتراضي.
مراجع وقراءات إضافية
OPRO (LLMs as Optimizers): Large Language Models as Optimizers (Yang et al., ICLR 2024). Using LLMs to optimize without gradients.
Theory of Mind in LLMs (Strachan et al.): Evaluating theory of mind in LLMs (Nature Human Behaviour, 2024). GPT-4 vs humans on ToM tasks.
Theory of Mind in LLMs (Kosinski): Evaluating large language models in theory of mind tasks (PNAS, 2024). GPT-4 solving 75% of false-belief tasks.
Whiteboard-of-Thought Prompting: Whiteboard-of-Thought (2024). LLMs drawing reasoning steps as images.
Reward Hacking: Reward Hacking in RL. Why rubrics fail.
METR Task Horizons: Measuring AI Ability to Complete Long Tasks (Kwa & West et al., 2025). Task horizons doubling every ~7 months.
Decision Transformer: Decision Transformer (Chen et al., NeurIPS 2021). RL as sequence modeling.
AlphaEvolve: AlphaEvolve. DeepMind's evolutionary coding agent.
Human Compatible: Russell, Stuart. Human Compatible: Artificial Intelligence and the Problem of Control (2019). The coffee example.
A Pattern Language: Alexander, Christopher. A Pattern Language (1977). The original pattern encyclopedia.
Part 1: Agent Autonomy - Part 1: Algorithmic Problems. The foundation.
Related Posts
استقلالية الـ Agent — الجزء الأول: كيف تحلّ المسائل الخوارزمية
استقلالية الـ agent مش لكل اشي. بس لشريحة معيّنة من الشغل — المسائل المحدودة اللي بدها ذكاء — هي بالظبط اللي بتحتاجه. خوارزميات، مقالات، demos، مواد تعليمية، خطط رحلات، صفحات ويب. هون كيف تعرف إيمتى توقف عن التوجيه وتبلّش توظيف.
برومبت الحب تبع ديفيش الأخطبوط
ديفيش كان مشغّل كرفان لحم أخطبوط مشبوه جوّا السيميوليشن. أحسن agent، تغطية عميقة. تمن مجسّات، تمن شغلات جانبية. قصة عن الحب، والـ AI، والضرايب.
أهلاً بأعظم هلوسة
مش فقاعة—الفقاعات بتنفقع وبترجع لطبيعتك. هاي سيمولاكرا. ما في طبيعي ترجعله.